
Within the Dutch government, more and more initiatives are emerging around the fact that something needs to fundamentally change when it comes to complexity within laws and regulations. This complexity is caused by the high number of laws and a lack of structure and classification within them. The government recognizes that these problems must be solved in the near future. Therefore, since 2014, there has been a triple helix collaboration – the Blue Chamber – that has devised an approach to solve this problem: Law analysis. Law analysis provides a solution that allows structure to be applied to legal texts through the use of the Legal Reference Model (JRM). Using the JRM, logical models and scenario plots can then be created.
While Law analysis provides a technical and logic-based approach to modeling laws, the ultimate goal is for Law analysis to be used by a multidisciplinary team (MDT), including policymakers. Currently, the logic texts generated by Law analysis are not in the form of the verbalizations that policymakers expect. Thus, there is still a crucial step to be taken: transforming the logical texts into text that is understandable to policymakers (the “comprehensible text”). These transformations will ultimately allow policymakers to make policy in a more efficient way.
These transformations are done using algorithms with AI techniques. Given that the algorithm has legal texts as input, the ethical and legal implications of using certain techniques have also been carefully considered. Therefore, this thesis first includes a preliminary examination of machine learning and logic-based techniques, as well as the ethical and legal implications of those techniques. Although machine-learning techniques (such as the transformers in ChatGPT) are currently very popular, preliminary research has shown that a logic-based technique is a better fit for this task – in particular, a rule-based model. One of the reasons for this is the explainability of rule-based models. This is because every decision of the rule-based model can be found in the code of the algorithm. This also allows logical accuracy to be maintained, since the algorithm does not make decisions that are not explicitly programmed.
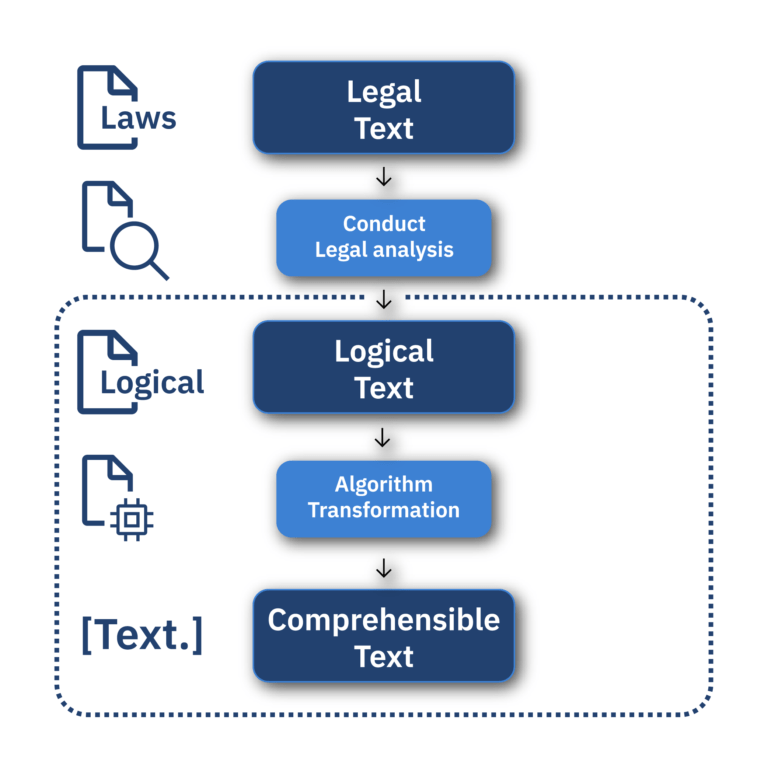
The algorithm works as follows: First, data (the logical texts) in the form of Word documents are fed into the algorithm, which then applies appropriate data transformations to read the document. Then the relevant information is extracted from the document and sorted, while preserving the underlying JRM logic. This information is then used in the generation of the comprehensible text, where the generation of this text is done using logic rules in the algorithm’s code.
After these texts are generated by the model, the level of the generated intelligible texts is examined using BLEU and SacreBLEU statistics. From these statistics, it can be concluded that the algorithm performs fine and the generated texts are always comprehensible, but there is a large variance in the grammatical correctness of the generated sentences.
Follow-up studies could therefore focus on adding additional rules and/or algorithms to take out even more grammatical errors, as well as evaluating the texts by decision makers in a practical study. In addition, an application has not yet been built around the current algorithm. An application could display the generated texts in a user-friendly way, possibly with new functionalities such as visualizations.

- Caspar Nijssen
- Technical university Eindhoven&Tilburg university
- 6 months
- Academic year 2023/2024
Status
Complete
100%
Are you interested in writing your thesis with us? Are you excited about the opportunity to be part of the Data Science & AI team from PNA? Learn more about our future projects!