
Binnen de Nederlandse overheid ontstaan steeds meer initiatieven rondom het feit dat iets fundamenteel moet veranderen als het aankomt op complexiteit binnen wet- en regelgeving. Deze complexiteit wordt veroorzaakt door het hoge aantal wetten en door een gebrek aan structuur en classificatie binnen deze wetteksten. De overheid erkent dat deze problemen in de nabije toekomst moeten worden opgelost. Daarom bestaat er sinds 2014 een triple helix samenwerking – de Blauwe Kamer – die een aanpak heeft bedacht om dit probleem op te lossen: Wetsanalyse. Wetsanalyse biedt een oplossing waarmee structuur kan worden toegebracht aan wetteksten door gebruik van het Juridisch Referentie Model (JRM). Aan de hand van het JRM kunnen vervolgens logische modellen en scenario plots worden gemaakt.
Hoewel Wetsanalyse een technische en logisch-gebaseerde aanpak biedt om wetten te modelleren, is het uiteindelijk de bedoeling dat Wetsanalyse gebruikt wordt door een multidisciplinair team (MDT), waaronder beleidsmakers. Op dit moment zijn de logische teksten die door Wetsanalyse gegenereerd worden niet in de vorm van de verbalisaties die beleidsmakers verwachten. Er is dus nog een cruciale stap die gezet moet worden: het transformeren van de logische teksten naar tekst die begrijpelijk is voor beleidsmakers (de ‘begrijpelijke tekst’). Deze transformaties zullen er uiteindelijk voor zorgen dat beleidsmakers op een efficiëntere manier beleid kunnen maken.
Deze transformaties gebeuren aan de hand van algoritmes met AI-technieken. Gezien het algoritme wetteksten als input heeft, is er ook zorgvuldig gekeken naar de ethische en wettelijke implicaties van het gebruik van bepaalde technieken. Daarom bevat deze thesis als eerst een vooronderzoek naar machine learning- en logica-gebaseerde technieken, en ook naar de ethische en wettelijke implicaties van die technieken. Hoewel machine-learning technieken (zoals de transformers in ChatGPT) momenteel zeer populair zijn, is gebleken uit het vooronderzoek dat een logica-gebaseerde techniek beter past bij deze taak – in het bijzonder een regel-gebaseerd model. Een van de redenen hiervoor is de verklaarbaarheid van regel-gebaseerde modellen. Iedere beslissing van het regel-gebaseerde model kan namelijk worden teruggevonden in de code van het algoritme. Hierdoor kan ook de logische nauwkeurigheid in stand blijven, het algoritme maakt immers geen beslissingen die niet expliciet geprogrammeerd zijn.
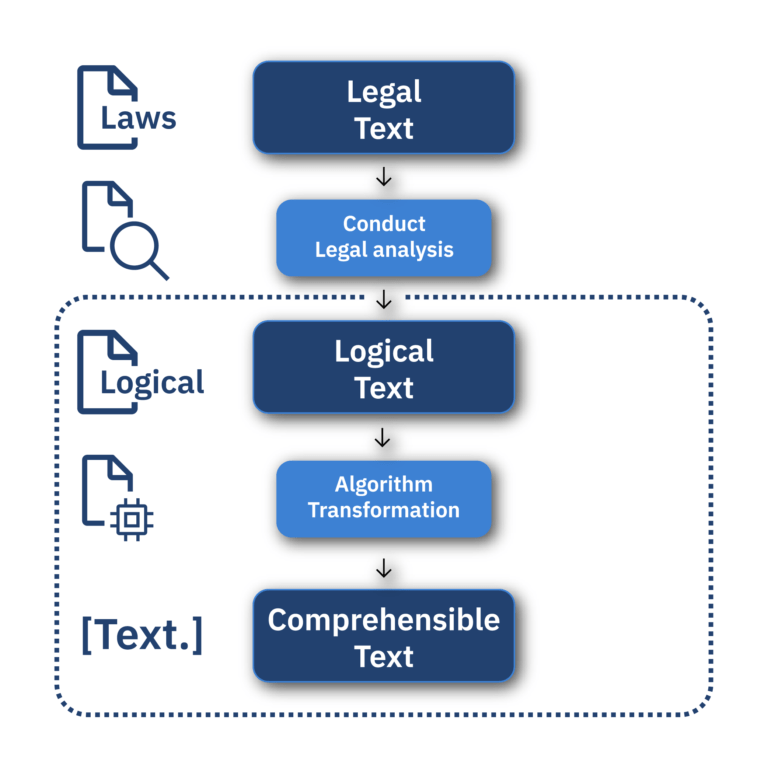
Het algoritme werkt als volgt: Eerst worden de data (de logische teksten) in de vorm van Word-documenten ingevoerd in het algoritme, dat vervolgens de juiste data transformaties toepast om het document te lezen. Daarna wordt de relevante informatie uit het document geëxtraheerd en gesorteerd, terwijl de onderliggende JRM-logica behouden blijft. Vervolgens wordt deze informatie gebruikt bij het genereren van de begrijpelijke tekst, waarbij het genereren van deze tekst plaatsvindt aan de hand van logische regels in de code van het algoritme.
Nadat deze teksten gegenereerd zijn door het model, wordt er gekeken naar het niveau van de gegenereerde begrijpelijke teksten aan de hand van BLEU en SacreBLEU statistieken. Uit deze statistieken kan worden geconcludeerd dat het algoritme prima presteert en dat de gegenereerde teksten altijd begrijpelijk zijn, maar dat er wel een grote variantie zit in de grammaticale correctheid van de gegenereerde zinnen.
Vervolgonderzoeken zouden zich daarom kunnen richten op het toevoegen van extra regels en/of algoritmes om nog meer grammaticale fouten eruit te halen, maar ook op het evalueren van de teksten door beleidsmakers in een praktisch onderzoek. Daarnaast is er om het huidige algoritme heen nog geen applicatie gebouwd. Een applicatie zou de gegenereerde teksten op een gebruiksvriendelijke manier kunnen weergeven, mogelijk met nieuwe functionaliteiten zoals visualisaties.

- Caspar Nijssen
- Technical university Eindhoven&Tilburg university
- 6 maanden
- Academisch jaar 2023/2024
Status
Complete
100%
Ben je geïnteresseerd in het schrijven van je scriptie bij ons? Ben je enthousiast over de mogelijkheid om deel uit te maken van het Data Science & AI team van PNA? Lees meer over onze toekomstige projecten!