
Nadine Beks van Raaij heeft zich tijdens haar master thesis op de Jheronimus Academy of Data Science ingezet op het versimpelen van ingewikkelde teksten. Specifiek teksten die gestuurd worden vanuit de overheid naar burgers, die ingewikkeld zijn om te begrijpen voor de meeste mensen.
Voor dit doel heeft Nadine verschillende ‘modellen’ ontwikkeld en getraind. Van een regel gebaseerd model tot aan een groot taalmodel. Deze modellen ontvangen een lastig te begrijpen tekst en vertalen deze naar een gemakkelijk te begrijpen tekst zonder dat de inhoud van de brief (en daarmee juridische geldigheid) verloren gaat. Om het probleem van vocabulaire aan te pakken, wat niet eenvoudigweg verandert kan worden naar eenvoudigere woorden, werd er een woordenlijst toegevoegd als input. Juridische termen bleven dus hetzelfde, maar werden in eenvoudigere termen uitgelegd voor de lezers, zodat ze de betekenis van het woord en de context eromheen kunnen begrijpen.
Om deze modellen te vergelijken, heeft ze eerst technische evaluatiemethoden toegepast, waarbij de output van de modellen met de BLEU-, BLEURT-, ROUGE- en LiNT-scores werden geëvalueerd. De eerste drie zijn gangbare evaluatiemethoden voor tekstvereenvoudiging, de laatste specifiek voor de leesbaarheid van de Nederlandse taal.
Daarnaast heeft ze interviews afgenomen met experts, zowel taalkundigen als juristen, om te testen of dat de vereenvoudigde teksten grammaticaal en lexicaal kloppen en ook dezelfde inhoud bevatten en daarmee juridisch geldig zijn.
Tot slot is er een lezersonderzoek gedaan onder mensen met verschillende achtergronden (in opleiding, leesuren, etc.) met een steekproefgrootte van 72 mensen, wat zorgt voor een prima vertegenwoordiging van de samenleving. Als resultaat vond ze dat het bekende GPT-model van OpenAI het beste presteerde ten op zichte van de andere modellen.
Het GPT-model is een groot taalmodel (LLM), dat dan ook gespecialiseerd is in taal gerelateerde zaken. Het GPT-model werd geoptimaliseerd door prompt engineering: het geven van een bepaalde taak aan het model, geschreven op een specifieke manier, zodat het model het doel duidelijk begrijpt en de gewenste resultaten kan leveren. Dit resulteerde in een model dat gespecialiseerd is in het vereenvoudigen van overheidsdocumenten.
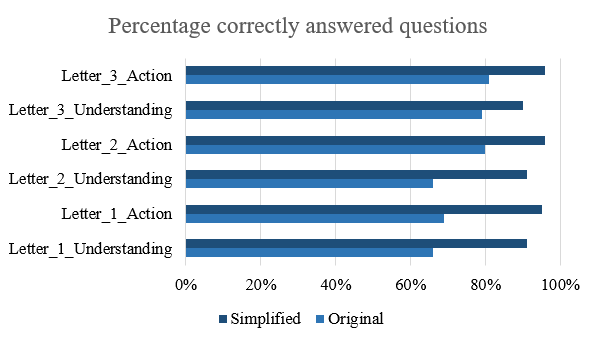
Het GPT-model presteerde niet simpelweg iets beter dan de andere modellen; het slaagde erin om het begrip van de tekst bij de deelnemers te verhogen van 60% naar gemiddeld 90% voor drie verschillende brieven, een aanzienlijke verbetering!
Zodoende heeft Nadine haar doel bereikt, en is verder gegaan met de implementatie van het beste model, zodat ze zoveel mogelijk mensen kan helpen en een positieve impact kan maken op hun leven.

- Nadine Beks van Raaij
- Jheronimus Academy of Data Science - JADS
- 12 maanden
- Academisch jaar 2022/2023
Status
Compleet
100%
Ben je geïnteresseerd in het schrijven van je scriptie bij ons? Ben je enthousiast over de mogelijkheid om deel uit te maken van het Data Science & AI team van PNA? Lees meer over onze toekomstige projecten!