
Het genereren van duidelijke en bruikbare tekstuele beschrijvingen van BPMN (Business Process Model and Notation) modellen is cruciaal voor een effectief begrip en gebruik van deze complexe bedrijfsmodellen. BPMN-modellen bevatten gedetailleerde informatie over bedrijfsprocessen die niet altijd direct toegankelijk is voor iedereen zonder aanvullende uitleg. Dit gebrek aan helderheid kan leiden tot misverstanden en inefficiënties bij het nemen van beslissingen binnen multidisciplinaire teams. Er is daarom behoefte aan methoden die begrijpelijke en consistente beschrijvingen genereren voor deze modellen.
Faysal heeft in zijn masterthesis de uitdaging onderzocht hoe automatisch accurate beschrijvingen van BPMN-modellen kunnen worden gegenereerd. Hij heeft drie benaderingen vergeleken: een template-gebaseerde aanpak, een benadering met grote taalmodellen (LLMs), en een hybride methode die elementen van beide technieken combineert. De template-gebaseerde aanpak maakt gebruik van vooraf gedefinieerde sjablonen om tekst te genereren, wat zorgt voor consistentie maar soms leidt tot minder flexibiliteit en creativiteit in de beschrijvingen. De LLM-benadering benut geavanceerde taalmodellen om contextueel relevante en coherente tekst te produceren, hoewel dit kan resulteren in inconsistentie of onnodige contextuele toevoegingen. De hybride aanpak probeert de voordelen van beide benaderingen te combineren, met als doel een evenwicht te vinden tussen structuur en flexibiliteit.
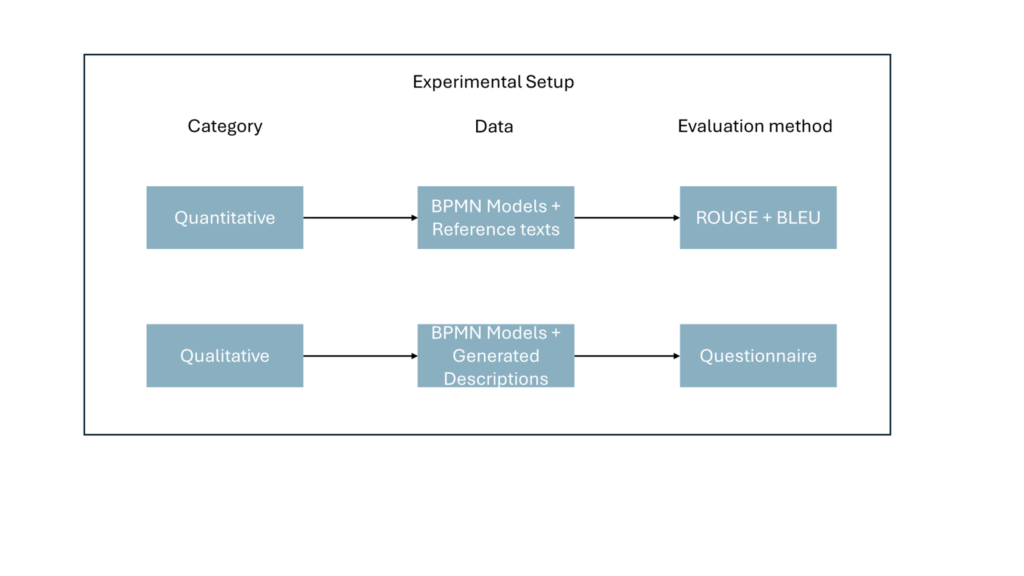
Om de gegenereerde beschrijvingen te evalueren, heeft Faysal zowel automatische als menselijke evaluatietechnieken gebruikt. Automatische evaluaties werden uitgevoerd met behulp van de BLEU- en ROUGE-scores, waarmee de nauwkeurigheid van de beschrijvingen werd gemeten door te kijken naar de overlap van woorden en zinsstructuren met referentieteksten. BLEU beoordeelt vooral de overeenkomsten in n-grams, terwijl ROUGE zich richt op hoe goed lange woordreeksen overeenkomen tussen de gegenereerde en referentiebeschrijvingen. Daarnaast werd een expert-survey uitgevoerd waarbij BPMN-experts de gegenereerde beschrijvingen beoordeelden op factoren zoals leesbaarheid, grammaticale correctheid en de mate waarin de beschrijvingen overeenkwamen met de BPMN-modellen. Deze combinatie van automatische en menselijke evaluaties bood een veelzijdig inzicht in de kwaliteit en bruikbaarheid van de gegenereerde tekstuele beschrijvingen.
De resultaten van het onderzoek bieden een overzicht van de sterke en zwakke punten van elke benadering. De template-gebaseerde aanpak blijkt betrouwbaar en consistent, hoewel deze aanpak soms beperkt is in flexibiliteit. Aan de andere kant verbeteren de LLM-benaderingen de leesbaarheid en grammaticale kwaliteit van de beschrijvingen, hoewel ze soms onnodige contextuele toevoegingen kunnen bevatten. De hybride aanpak blijkt effectief in het combineren van de voordelen van beide methoden, wat suggereert dat een gebalanceerde benadering de meest geschikte oplossing kan zijn voor verschillende scenario’s.
Om de gegenereerde beschrijvingen correct te implementeren, is het belangrijk om de gekozen methode af te stemmen op de specifieke behoeften van het project en de gebruikers. Hierbij is het essentieel om rekening te houden met de sterke en zwakke punten van elke benadering, zodat organisaties weloverwogen keuzes kunnen maken over welke methode het meest geschikt is voor het genereren van tekstuele beschrijvingen van BPMN-modellen. Dit kan helpen bij het verbeteren van de communicatie en documentatie, waardoor de complexiteit van bedrijfsprocessen toegankelijker wordt voor een breder publiek. Het onderzoek van Faysal biedt waardevolle inzichten en praktische aanbevelingen voor het verbeteren van de tekstuele representatie van BPMN-modellen in de praktijk.

Ben je geïnteresseerd in het schrijven van je scriptie bij ons? Ben je enthousiast over de mogelijkheid om deel uit te maken van het Data Science & AI team van PNA? Lees meer over onze toekomstige projecten!